
Menu
Close
Module 376 Collecter et analyser des données
Compétence opérationnelle c3: Collecter les données
Si les données et informations nécessaires font défaut, les développeurs de business numérique CFC se chargent de les collecter de manière autonome:
Ils planifient la collecte des données et l’effectuent au moyen de la méthode appropriée. Pour ce faire, ils recourent typiquement à des interviews ou à des sondages simples. Ils enregistrent les données collectées sous une forme ad hoc et dans la qualité appropriée. Lors de la collecte des données, ils procèdent de manière analytique et avec le doigté nécessaire.
Compétence opérationnelle c6: Exploiter les données et établir des rapports simples
Les développeurs de business numérique CFC procèdent à des exploitations de données aisément compréhensibles:
Ils déterminent les outils appropriés, exploitent les données à l’aide de requêtes ciblées, établissent des rapports clairs en fonction des questions traitées et en tirent une conclusion concise. Ils documentent les résultats de manière compréhensible pour autrui. Ils peuvent aussi traiter de questions plus complexes et, si nécessaire, demander un soutien.
c3.1 En fonction des exigences, ils planifient la collecte des données (y c. mode de collecte, sources, format cible des données).
c3.2 Ils colt les données dans le cadre d’interviews avec les personnes sélectionnées.
c3.3 Ils relèvent les données par le biais d’un sondage simple.
c3.4 Ils enregistrent les données recueillies dans la forme et la qualité appropriées.
c6.1 Ils déterminent les outils appropriés (p. ex. PowerBI, Tableau, Qlik) pour exploiter les données.
c6.2 Ils exploitent les données à l’aide de requêtes ciblées (p. ex. au moyen de SQL).
c6.3 Ils établissent des rapports simples et clairs selon les objectifs et les questions définis.
c6.4 Ils tirent une conclusion concise de l’exploitation des données et la consignent de manière compréhensible et étayée.
Pour chaque tâche fournir un mini rapport qui décrit et illustre votre travail. Ces rapports devront être fournis en fin de cours lors de la clôture.
Jour 1 : réaliser un sondage
Phase 2
1 questionnaire / sondage, présentation des questions/champs
2 des réponses au questionnaire
3 une critique constructive de votre questionnaire
4 un rapport avec analyse des données récoltées (ou fictives)
1 présentation rapide de la structure de données spotify
2. un dossier pour client CIE Radio sur PowerPoint
1 un journal de travail (oral ou écrit)
La taille d’une personne, exprimée en centimètres (par exemple : 175 cm).
C’est une donnée quantitative car elle est mesurable numériquement et permet de faire des opérations mathématiques comme la moyenne, l’écart-type, etc.
Types
Peut prendre uniquement des valeurs entières (souvent issues d’un comptage).
Exemple :
Nombre d’enfants, nombre de voitures, nombre de messages reçus
Peut prendre toutes les valeurs possibles dans un intervalle (même des décimales)
Exemple :
Taille (ex : 175,2 cm), poids (ex : 68,5 kg), température

Une donnée qualitative est une information qui décrit une qualité, une caractéristique ou une catégorie. Elle ne peut pas être mesurée numériquement, mais elle permet de classer ou nommer des éléments.
Exemples :
Nationalité : suisse, française, italienne…
Genre : homme, femme…
Musique préférée : jazz, rock, classique…
État civil : célibataire, marié, divorcé
Donnée qualitative sans ordre particulier entre les valeursCouleur des yeux : bleu, vert, marron
Genre : homme, femme
Nationalité : suisse, italienne, française
On ne peut pas classer ou hiérarchiser les valeurs
Donnée qualitative avec un ordre logique entre les valeurs
Niveau d’étude : primaire, secondaire, universitaire
Niveau de satisfaction : faible, moyen, élevé
Taille de t-shirt : S, M, L, XL
On peut classer les valeurs selon un ordre
But : Résumer et décrire les données observées.
Outils : Moyenne, médiane, écart-type, tableaux, graphiques (histogramme, diagramme circulaire…)
Exemple : Moyenne d’âge des étudiants d’une classe, répartition par genre.
But : Découvrir des tendances, structures ou relations cachées dans les données, sans hypothèse préalable.
Outils : Visualisations, corrélations, matrices de dispersion, ACP (analyse en composantes principales), regroupements (clusters).
Exemple : Explorer un grand jeu de données pour identifier des profils types de consommateurs.
But : Faire des prédictions ou des généralisations à partir d’un échantillon vers une population.
Outils : Tests d’hypothèse (t-test, chi², ANOVA), intervalles de confiance, régressions.
Exemple : Estimer la proportion de personnes favorables à une réforme dans une population, à partir d’un sondage.
But : Prévoir des résultats futurs en se basant sur des données passées.
Outils : Régressions, arbres de décision, modèles de machine learning (réseaux de neurones, forêts aléatoires…)
Exemple : Prédire le chiffre d’affaires d’un magasin pour le mois prochain.
But : Recommander des actions en se basant sur des prédictions et des simulations.
Outils : Optimisation, scénarios, algorithmes de décision.
Exemple : Proposer le meilleur itinéraire de livraison en fonction du trafic et des coûts.
L’analyse descriptive consiste à résumer et présenter les données de manière simple et claire, sans en tirer de conclusions. Elle permet de comprendre les grandes tendances d’un ensemble de données.
Moyenne, médiane, mode
Pourcentages
Tableaux, graphiques (camembert, histogramme…)
Calculer l’âge moyen des élèves d’une classe
Afficher la répartition des réponses à un sondage
L’analyse inférentielle permet de tirer des conclusions ou de faire des généralisations sur une population à partir d’un échantillon de données.
L’analyse prédictive utilise les données passées pour prévoir des événements futurs ou des tendances.
L’analyse prescriptive recommande les meilleures actions à entreprendre pour atteindre un objectif, souvent en optimisant des processus ou des ressources.
Il existe de nombreux outils qui proposent d'analyser leurs propres données, je citerai
Salesforce : qui analyse le comportement des clients
![]()
et
![]()
Google Ad : qui analyse très bien le comportement des internautes autour d'un ensemble de sites
Je relèverai ici 2 langages de programmation orientés vers l'analyse des données
Python
![]()
et
le langage R
![]()
Ces langages sont très ouverts, mais demandent un apprentissage relativement long.
Ces outils sont payants dans leur version complète, mais offrent un panel de fonctionnalités très riche.



![]()
Puissant, universel et facilement ccessible.
Dans un projet d'envergure, Excel sera employé conjointement avec les autre soutils.
Voici les règles principales à suivre pour réaliser un bon sondage et traiter les données avec des outils statistiques :
Pourquoi faire ce sondage ?
Quel type d’information ou de décision souhaitez-vous obtenir ?
Méthode d’échantillonnage : Utilisez des méthodes d’échantillonnage appropriées (échantillonnage aléatoire, stratifié, etc.) pour éviter les biais.
L’échantillon doit être suffisamment grand pour avoir une bonne représentativité de la population cible.
Éviter les ambiguïtés : Les questions doivent être simples et compréhensibles par tous les répondants.
Questions fermées vs questions ouvertes : Choisissez selon le type de données que vous souhaitez recueillir (quantitatives ou qualitatives).
Les participants doivent savoir comment leurs réponses seront utilisées.
Il est crucial de protéger les données personnelles des répondants.
Réalisez un test pilote sur un petit échantillon pour vérifier la clarté des questions et identifier d’éventuelles erreurs ou biais.
Les données doivent être fiables : assurez-vous que les répondants comprennent les questions de manière similaire et qu’il n’y ait pas de confusion.
Évitez les biais : comme les biais de sélection ou de réponse.
Uniformité dans la manière de collecter les données (en ligne, téléphone, face-à-face, etc.) pour éviter de fausser les résultats.
Nettoyage des données : Vérifiez les erreurs et anomalies (données manquantes, incohérences).
Choisissez les outils statistiques adaptés selon les objectifs du sondage :
Moyennes, médianes, modes pour des analyses descriptives
Tests d’hypothèses pour des analyses inférentielles
Modèles prédictifs si vous souhaitez faire des prédictions basées sur les résultats.
Évitez de généraliser au-delà de la population cible.
Prenez en compte les limites méthodologiques de votre sondage, telles que la taille de l’échantillon ou les biais potentiels.
Utilisez des graphismes et des tableaux pour rendre les résultats facilement accessibles et compréhensibles par tous, même ceux sans expertise statistique.

1. Transparence de l’information : Clarifiez l’objectif de l’étude et l’utilisation des données de manière explicite. Mettez en place des politiques de confidentialité transparentes et obtenez le consentement des participants, assurant ainsi une communication ouverte et honnête.
2. Anonymat dans la collecte : Préservez la confidentialité en utilisant des méthodes de collecte anonymes. Encouragez l’anonymat, en particulier pour des sujets délicats, et ajustez les mesures de protection en fonction du degré de sensibilité des informations collectées.
3. Protection des données : Formez le personnel sur les bonnes pratiques de gestion des données. Établissez des contrôles d’accès stricts pour garantir la sécurité des informations. Développez un plan solide pour l’élimination ou la conservation sécurisée des données, renforçant ainsi la protection des données sensibles.
4. Respect des réglementations : Intégrez dès la conception des questionnaires les normes de protection des données. Restez informé des évolutions légales, en particulier en ce qui concerne les réglementations en vigueur, pour assurer une conformité continue.
5. Usage de panels préétablis : Simplifiez le processus d’étude en privilégiant l’utilisation de panels existants. Optez pour des panels gérés activement afin de garantir la qualité des résultats. Cultivez la confiance des participants pour établir des partenariats durables.
(Elles nécessitent des données, souvent issues d'un échantillon ou d'une population, pour y répondre)
(Elles concernent des faits uniques ou des opinions, pas besoin de recueillir des données)
Pour des données faciles à recueillir et à analyser, privilégiez les questions fermées. En effet, elles produisent des données quantitatives qui peuvent servir à mesurer des variables.
En règle générale, essayez de vous limiter à deux questions ouvertes par sondage ou enquête. Si possible, placez-les à la fin du sondage.
Adoptez un ton objectif en vous abstenant d’exprimer votre opinion. Pour cet exemple, formulez votre question ainsi.
es participants doivent avoir l’opportunité de proposer des réponses honnêtes et réfléchies, seul gage de crédibilité de votre sondage.
Ne pas poser une question double, c’est-à-dire une question à deux volets, qui demande aux participants d’évaluer deux choses différentes en même temps.
Répondre cinquante fois à la même question finirait probablement par agacer.
Parfois, les participants ne connaissent pas les réponses à vos questions. Peut-être sont-ils gênés par certaines d’entre elles et ne souhaitent pas y répondre. Pourtant, vous avez besoin de leur feedback.
Partagez votre sondage avec vos collègues ou votre entourage avant de l’envoyer à votre population cible. Il suffit parfois d’un regard neuf ou d’un avis objectif pour repérer des erreurs.
Retirez les colonnes qui ne sont pas utiles pour l’analyse.
Plusieurs options s’offrent à vous :
5. Uniformiser les formats de données
Dates : assurez-vous qu’elles sont toutes au même format (YYYY-MM-DD par exemple).
Nombres : remplacez les virgules par des points si nécessaire (1,5 → 1.5).
Texte : appliquez une casse cohérente (tout en minuscules, par exemple).
Transformez les réponses textuelles en codes numériques pour l’analyse :
Notez toutes les transformations apportées au fichier :
Cela vous permettra de reproduire ou justifier vos choix plus tard.
import pandas as pd
import numpy as np
# 1. Charger le fichier Excel
df = pd.read_excel("donnees_avec_legers_problemes.xlsx")
# 2. Vérifier et convertir les types de données
df['age'] = pd.to_numeric(df['age'], errors='coerce')
df['revenu_mensuel'] = pd.to_numeric(df['revenu_mensuel'], errors='coerce')
df['date_naissance'] = pd.to_datetime(df['date_naissance'], errors='coerce')
# 3. Nettoyer les valeurs aberrantes
# Supprimer ou corriger les âges aberrants
df.loc[(df['age'] < 0) | (df['age'] > 100), 'age'] = np.nan
# Supprimer les revenus excessifs (>20 000€)
df.loc[df['revenu_mensuel'] > 20000, 'revenu_mensuel'] = np.nan
# Supprimer les dates de naissance irréalistes
df.loc[(df['date_naissance'].dt.year < 1900) | (df['date_naissance'].dt.year > 2024), 'date_naissance'] = pd.NaT
# 4. Gérer les valeurs manquantes
# Imputation simple : moyenne pour âge et revenu
df['age'].fillna(df['age'].mean(), inplace=True)
df['revenu_mensuel'].fillna(df['revenu_mensuel'].mean(), inplace=True)
# Suppression des lignes sans date de naissance
df = df.dropna(subset=['date_naissance'])
# 5. Vérification du genre (doit être "Homme" ou "Femme")
df['genre'] = df['genre'].where(df['genre'].isin(['Homme', 'Femme']))
# 6. Exporter le fichier nettoyé
df.to_excel("donnees_nettoyees.xlsx", index=False)
print("✅ Données nettoyées enregistrées dans 'donnees_nettoyees.xlsx'")
Afin d'avoir un niveau suffisant avec Excel, mais aussi les autres produits tels que Tableau ou Power BI il faudrait connaître les 4 points suivants suivants :
Savez-vous :
Si non une petite mise à niveau s'impose

Incrémenter les valeurs - Télécharger
Référencer des cellules et des plages - Télécharger
Calculs simples - Télécharger
Calculs sur des ensembles - Télécharger
Exercices sur les fonctions de base : Télécharger (SOMME/MOYENNE/SI/NB)
Créer des tableaux de données no tableau - Télécharger
Créer des tableaux de données // Médailles - Télécharger
| Raccourci | Définition |
| Tab | passer à la cellule suivante (à droite) |
| Shift+Tab | passer à la cellule précédente (à gauche) |
| Ctrl+Flèche | atteindre l’extrémité d’un tableau de données (ou de la feuille) |
| Shift+Flèche | sélectionner les données des cellules adjacentes |
| Ctrl+Shift+Flèche | sélectionner un tableau de données facilement sur Excel |
| Ctrl+A | sélectionner tout un tableau sur Excel |
| Touche Suppr | effacer le contenu d’une cellule Excel |
| Ctrl+Molette | zoomer ou dézoomer sur Excel |
| Ctrl+O | ouvrir une feuille de calcul |
| Ctrl+W | fermer une feuille de calcul |
| Ctrl+S | sauvegarder un fichier Excel |
| Ctrl+F | rechercher et remplacer une valeur sur Excel |
| Ctrl+N | créer un nouveau classeur |
| Ctrl+Z | annuler la dernière action |
| Ctrl+Y | effectuer une action précédemment annulée |
Télécharger le fichier d'exercices et ressortir les informations suivantes
1. Modifiez les données initiales afin de pouvoir les transformer en tableau
2. Modifiez le nom du tableau en "gender data" (pas d'accents)
3. Le football apparait 2 fois, supprimez les doublons
4. Ajoutez la ligne de total et faites la somme de chaque colonne
5. Créez une nouvelle colonne calculant le pourcentage de femmes pour chaque sport
6. Dans la cellule "maximum d'athlètes", calculez le nombre maximum d'athlètes pour un sport
=nbval()
=nb()
=nb.vide()
=nb.si(;">100")
=nb.si.ens()
=min()
=max()
=min.si.ens()
=moyenne.si.ens()
=mediane()
=mode()
=ecartype.standard()
Un nouvelle radio va commencer la diffusion dans la région lémanique, tant en France qu'en Suisse. Son objectif est essentiellement musical et vise essentiellement les lieux collectifs (bars, restaurants, boutiques, etc.)
Son choix initial est de diffuser la musique actuelle pop, rock, latino et dance essentiellement. Son objectif et de s'adapter aux heures de la journée pour diffuser une musique énergique. L'énergie de la musique est importante aux yeux de la direction.
Votre mission est de valider le choix de la direction de la radio en vous basant sur les statistiques d'écoute de Spotify. Et surtout de conseiller la Direction qui est issue d'un milieu éloigné de la radio, la presse écrite.
Les données proviennent du site :
https://charts.spotify.com/home
Qui vous donne semaine après semaine les charts
Ici, pour l'exercice, nous récupérons le travail d'un informaticien qui a compilé les charts semaine après semaine sur plusieurs mois.
Nous vous avons également un peu facilité la tâche en tentant de traduire les colonnes de la manière la plus fidèle possible
Etablir un document (Word ou autre) pour décrire le fichier :
Pur chaque colonne déterminer si la données
est Quantitative ou Qualitative
et si Quantitative, est-elle discrète ou continue
Donner les informations suivantes
Questions posées par la Direction de Radio CIE ?
Exemple :
Est-ce que ce sont seulement les superstars qui se retrouvent dans le Top 200?
Y a-t-il un style de musique qui donne plus d'énergie que d'autres ?
Sont-ce uniquement les musiques qui viennent de sortir qui se trouvent au Top ?
Définition du jeu de données :
Publier un beau rapport (PPW)
Ajouter, par exemple, le poids de chaque genre musical dans le Top 200
Le lien entre le genre de musique et l'écoute
Le lien entre le genre de musique et la positivité.
x = "Hello World" str
x = 20 int
x = 20.5 float
x = 1j complex
x = ["apple", "banana", "cherry"] list
x = ("apple", "banana", "cherry") tuple
x = range(6) range
x = {"name" : "John", "age" : 36} dict
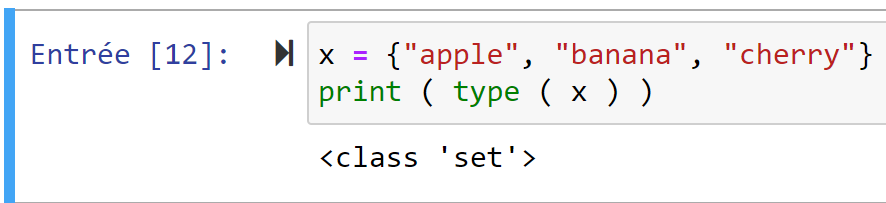
x = {"apple", "banana", "cherry"} set
x = frozenset({"apple", "banana", "cherry"}) frozenset
x = True bool
x = b"Hello" bytes
x = bytearray(5) bytearray
x = memoryview(bytes(5)) memoryview
x = None NoneType
print( type ( x ) )
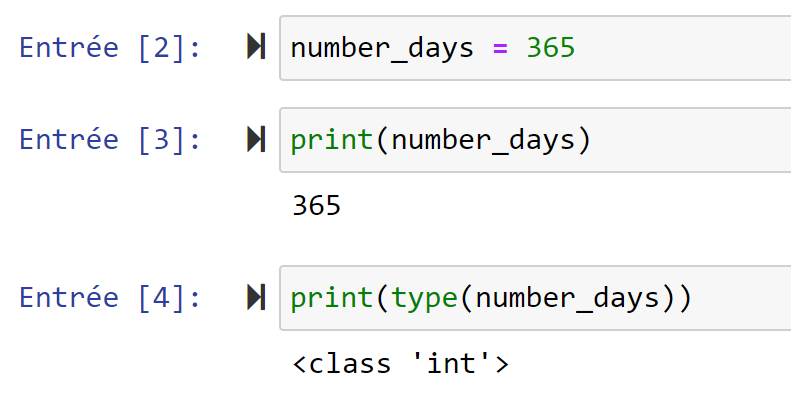
nb_jours = 365
print( nb_jours )
print( type (nb_jours ) )
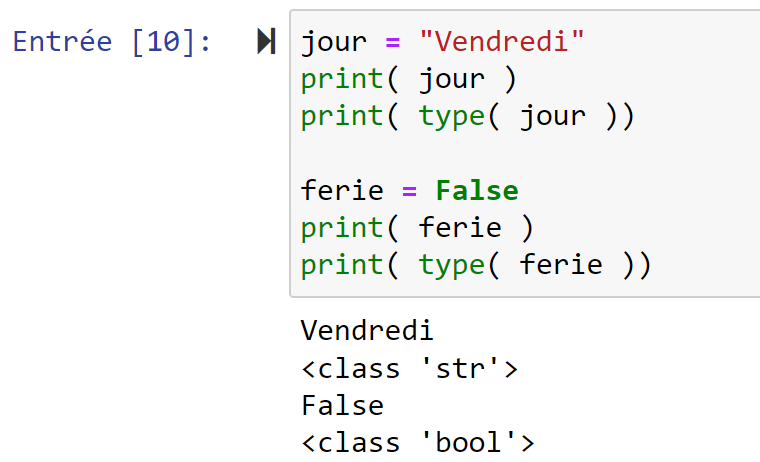
jour = "Vendredi"
print( jour )
print( type( jour ))
ferie = False
print( ferie )
print( type( ferie ))
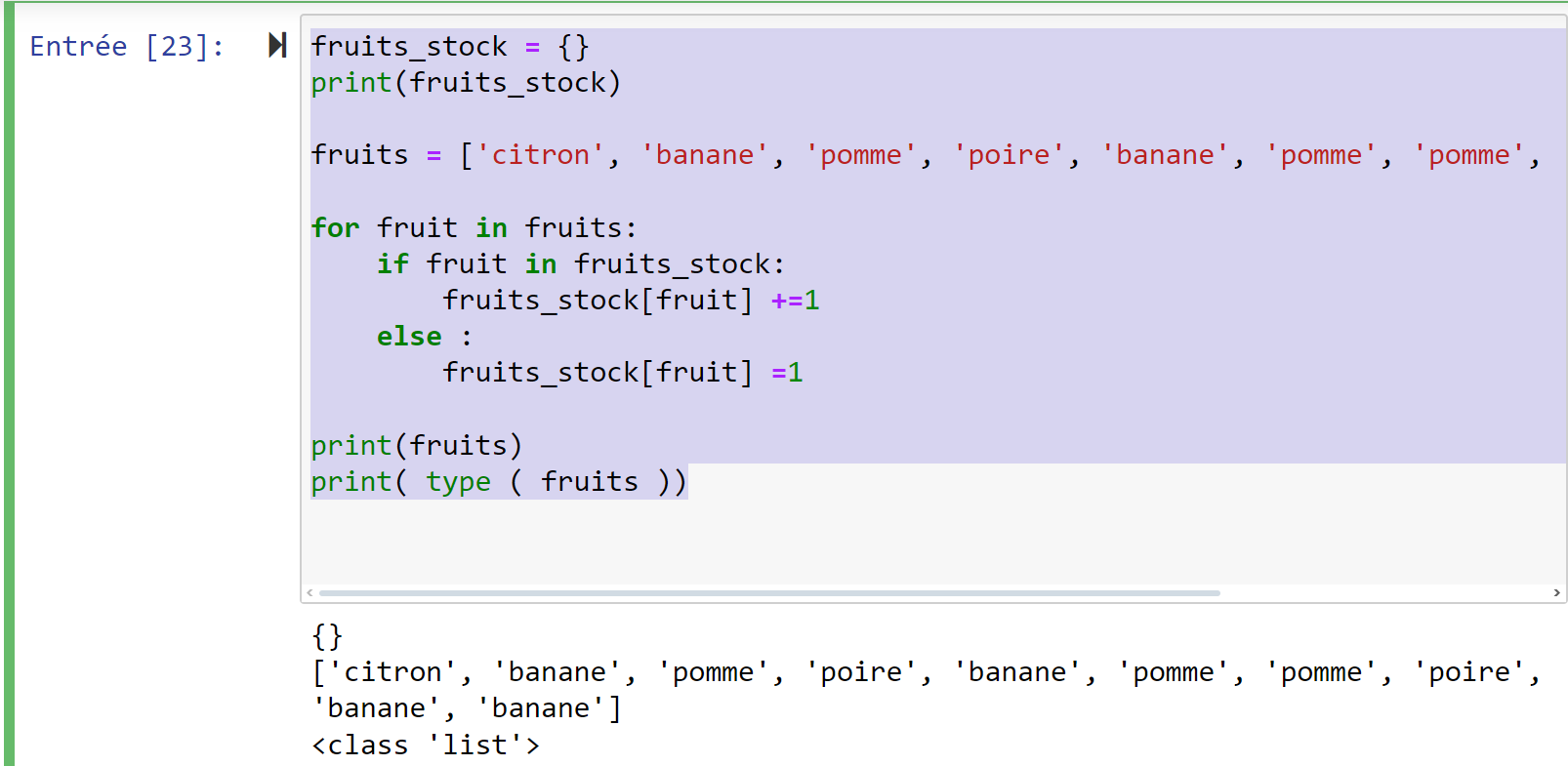
fruits_stock = {}
print(fruits_stock)
fruits = ['citron', 'banane', 'pomme', 'poire', 'banane', 'pomme', 'pomme', 'poire', 'banane', 'banane']
for fruit in fruits:
if fruit in fruits_stock:
fruits_stock[fruit] +=1
else :
fruits_stock[fruit] =1
print(fruits)
print( type ( fruits ))

fruits = ['citron', 'banane', 'pomme', 'poire', 'banane', 'pomme', 'pomme', 'poire', 'banane', 'banane']
fruits.append('framboise')
print(fruits)

# NumPy (Numerical Python) est une bibliothèque utilisée pour :
# Manipuler des tableaux/matrices de données (appelés ndarray)
# Faire des opérations mathématiques rapides
# Travailler efficacement avec des grandes quantités de données numériques
import numpy as np
# Créer un tableau numpy
a = np.array([1, 2, 3, 4, 5])
# Quelques opérations
print("Tableau :", a)
print("Somme :", np.sum(a))
print("Moyenne :", np.mean(a))
print("Max :", np.max(a))
import numpy as np
liste = [1, 2, 3]
tableau = np.array(liste)
# Multiplie chaque élément par 2
print(liste * 2) # => [1, 2, 3, 1, 2, 3] (concatène)
print(tableau * 2) # => [2 4 6] (multiplie)
import numpy as np
# Création d'un tableau 1D
mon_tableau = np.array([10, 20, 30, 40, 50])
# Afficher le tableau
print("Tableau :", mon_tableau)
# Afficher le type de données de chaque élément
print("Type des éléments :", mon_tableau.dtype)
# Afficher le type Python de l'objet (structure)
print("Type du tableau :", type(mon_tableau))
import numpy as np
# Création d'un tableau 2D
mon_tableau_2d = np.array([[10, 20, 30], [40, 50, 60]])
# Afficher le tableau 2D
print("Tableau 2D :\n", mon_tableau_2d)
# Afficher le type de données des éléments
print("\nType des éléments :", mon_tableau_2d.dtype)
# Afficher le type Python de l'objet (structure)
print("\nType du tableau :", type(mon_tableau_2d))
print(matrice.shape)
import numpy as np
# Lire un fichier CSV avec numpy
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding=None, skip_header=1)
# Afficher le tableau chargé
print(tableau)
# Afficher le type du tableau
print(type(tableau))
fichier.dtype
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Afficher le tableau chargé
print(tableau)
# Afficher le type du tableau
print(type(tableau))
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Extraire la 2ème ligne (index 1)
deuxieme_ligne = tableau[1]
# Afficher la 2ème ligne
print("Deuxième ligne :", deuxieme_ligne)
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Extraire la valeur de la 2ème ligne et 3ème colonne (index 1, 2)
valeur = tableau[1, 2]
# Afficher la valeur extraite
print("Valeur extraite :", valeur)
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Sélectionner la 2ème colonne (index 1)
colonne_2 = tableau[:, 1]
# Afficher la colonne sélectionnée
print("2ème colonne :", colonne_2)
# Sélectionner plusieurs colonnes :
tableau[:, [0, 1]].
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Sélectionner la 2ème ligne (index 1)
ligne_2 = tableau[1]
# Afficher la ligne sélectionnée
print("2ème ligne :", ligne_2)
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Sélectionner les 1ère et 2ème lignes (index 0 et 1)
# Sélectionner les 2ème et 3ème colonnes (index 1 et 2)
selection = tableau[0:2, 1:3]
# Afficher la sélection
print("Sélection des lignes et colonnes spécifiques :\n", selection)
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Filtrer les lignes où l'âge (2ème colonne) est supérieur à 30
filtre = tableau[tableau[:, 1] > 30]
# Afficher le tableau filtré
print("Tableau filtré :\n", filtre)
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Filtrer les lignes où l'âge est supérieur à 25 et la ville est "Paris"
filtre = tableau[(tableau[:, 1] > 25) & (tableau[:, 2] == 'Paris')]
# Afficher le tableau filtré
print("Tableau filtré sur 2 critères :\n", filtre)
fivhier2= fichier.copy()
import numpy as np
# Lire le fichier CSV avec l'encodage UTF-8
fichier = 'fichier.csv'
tableau = np.genfromtxt(fichier, delimiter=',', dtype=None, encoding='utf-8', skip_header=1)
# Remplacer les âges supérieurs à 30 par 30
tableau[tableau[:, 1] > 30, 1] = 30
# Afficher le tableau modifié
print("Tableau après remplacement :\n", tableau)